 Zen monks have been using a tool called a ‘koan’ for hundreds of years to assist them in reaching enlightenment. These koans are like riddles or stories that can only be solved by letting go of ones narrowing believes and stories about how things should be. Zen students sit in silent meditation and observe how the koan is working on them, slowly transforming their way of looking at the world and revealing a tiny piece of the path to nirvana, that place of no suffering.
Zen monks have been using a tool called a ‘koan’ for hundreds of years to assist them in reaching enlightenment. These koans are like riddles or stories that can only be solved by letting go of ones narrowing believes and stories about how things should be. Zen students sit in silent meditation and observe how the koan is working on them, slowly transforming their way of looking at the world and revealing a tiny piece of the path to nirvana, that place of no suffering.
“Zen is like a man hanging by his teeth in a tree over a precipice. His hands grasp no branch, his feet rest on no limb, and under the tree another man asks him, ‘Why did Bodhidharma come to China from the West?’ If the man in the tree does not answer, he misses the question, and if he answers, he falls and loses his life. Now what shall he do?”
— Zen Koan — Case 5 of the Gateless Gate Collection.
Zen and Cyber Security
You might wonder what that has to do with cyber security. With the increased popularity of deep learning and the omni presence of the term artificial intelligence (AI), a lot of security practitioners are tricked into believing that these approaches are the magic silver bullet we have been waiting for to solve all of our cyber security challenges. But just like a koan, deep learning (or any other machine learning approach) is just a tool. It’s a tool you have to know how to apply in order for it to reveal true insight. And it’s not the only tool we need to use. We need to mix in experience. We have to work with experts to capture their knowledge for the algorithms to reveal actual security insights or issues. Just like with koan study, you work with a teacher (the expert) to have him guide you on your journey.
AI in Cyber Security
Where do we stand today with artificial intelligence in cyber security? First of all, I will stop using the term artificial intelligence and revert back to using the term machine learning. We don’t have AI (or to be precise AGI) yet, so let’s not distract ourselves with these false concepts.
Where are we with machine learning in security? To answer that question, we first need to look at what our goal is for applying machine learning to cyber security problems. To make a broad statement, we are trying to use machine learning to find anomalies. More precisely we use it to identify malicious behavior or malicious entities; call them hackers, attackers, malware, unwanted behavior, etc. But beware! To find anomalies, one of the biggest challenges is to define what’s normal. For example, can you define what is normal behavior for your laptop day in — day out? Don’t forget all the exceptional scenarios when you are traveling; or think of the time that you downloaded some ‘game’ from the Internet. How do you differentiate that from a download triggered by some malware? Put in abstract terms, interesting security events are not statistical anomalies. Only a subset of those are interesting. An increase in network traffic might be statistically interesting, but from a security point of view, that rarely ever represents an attack.
Applying Machine Learning To Security
In a somewhat simplified world, we can partition security use-cases into two groups: The problems where machine learning has made a difference and the ones where machine learning has been tried, but will likely never yield usable results. In machine learning lingo, from a supervised perspective, the former category is comprised of all the problems where we have “good”, labeled data. The latter is where we don’t have that. The unsupervised side looks a bit different. There we have to distinguish among the different unsupervised approaches. For this conversation, let’s consider clustering, dimensionality reduction, and association rule learning as the main approaches within unsupervised learning. All of these approaches are useful to make large dataset easier to analyze or understand. They can be used to reduce the number of dimensions or fields of data to look at (dimensionality reduction) or group records together (clustering and association rules). However, these algorithms are of limited use when it comes to identifying anomalies or ‘attacks’.
The following diagram summarizes this again:
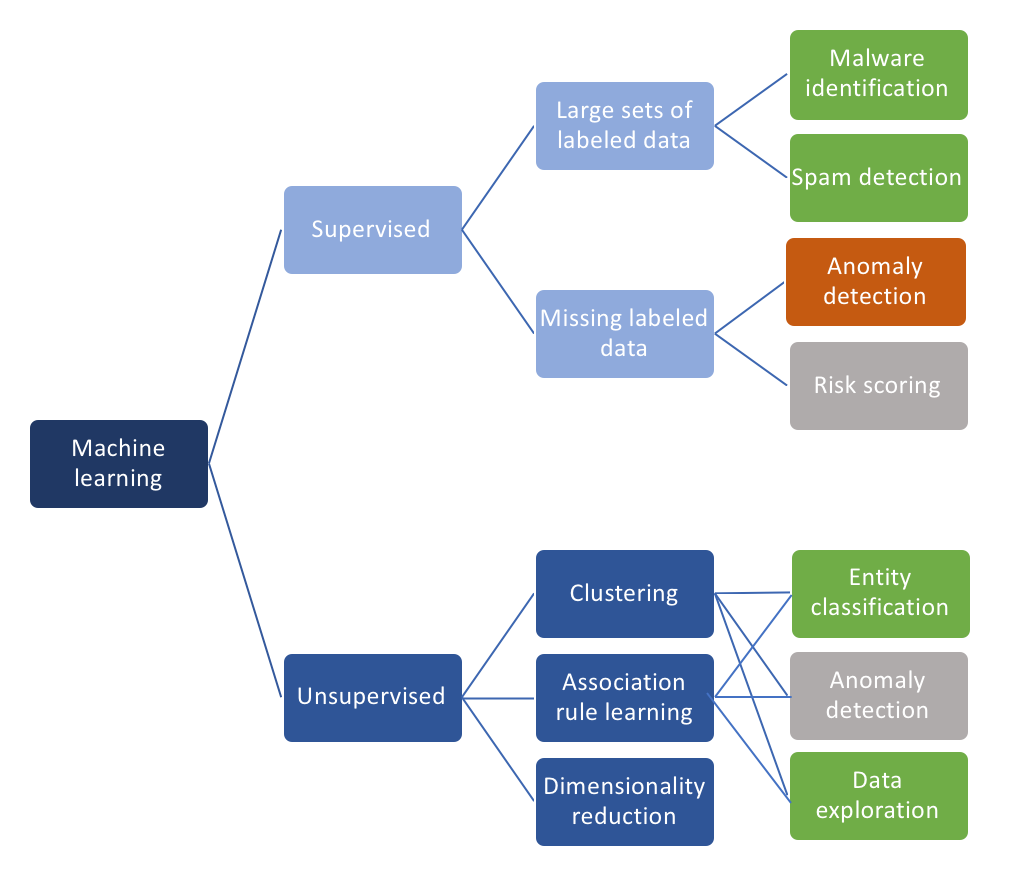
Diagram 1 — Incomplete view of machine learning algorithms and applications in security.
Supervised Machine Learning
Let’s have a quick look at the different groups of machine learning algorithms, starting with the supervised case. This is where machine learning has made the biggest impact in cyber security. The two poster use-cases are malware classification, or the classification of files, and spam detection. The former is the problem of identifying whether a file
is benign — we can execute it without having to worry about any ‘side effects’ — or if it is malware that will have a negative impact when we run it. Today’s approaches in this area have greatly benefited from deep learning where it has helped drop false positive rates to very manageable numbers while also reducing the false negative rates at the same time. Malware identification works so well because of the availability of millions of labeled samples (from both malware and benign applications). These samples allow us to train deep belief networks extremely well. The problem of spam identification is very similar in the sense that we have a lot of training data to teach our algorithms right from wrong.
Where we don’t have great training data is in most other areas. For example, in the realm of detecting attacks from network traffic. We have tried for almost two decades to come up with good training data sets for these problems, but we still do not have a suitable one. The last data set we thought was decent was the MIT LARIAT data set, which turned out to be significantly biased. It’s a really hard, if not impossible, problem to assemble a good training data set. And without one, we cannot train our algorithms. There are other problems like the inability to deterministically label data, the challenges associated with cleaning data, or understanding the semantics of a data record. But those are out of scope for this article.
Unsupervised Machine Learning
On the unsupervised side, let’s start with dimensionality reduction. Applying it to security data works pretty well, but again, it doesn’t really bring us any closer to finding anomalies in our data set. The same is true for association rules. They help us group data records, such as network traffic, but how do we assess anomalies with this information? Clustering could be interesting to find anomalies. Maybe we can find ways to cluster ‘normal’ and ‘abnormal’ entities, such as users or devices? It turns out that the fundamental problems with clustering in security are distance functions and the ‘explainability’ of the clusters. If you are interested in the details of that, you can find more information about the challenge with distance functions and explainability in this blog post.
Context and Knowledge
The above algorithms are tools that could potentially be useful for detecting attacks if used in the right way. Aside from the challenges mentioned already, there are some other significant ingredients that we are missing. The first one is context. Context is anything that helps us better understand the role of the entities involved in the data, such as information about devices, applications, or users. Context for devices includes things like a device’s role, it’s location, it’s owner, etc. Rather than looking at network traffic logs in isolation, we need to add context to make sense of the data. Is a device supposed to respond to DNS queries? If you know that it is a DNS server, this is absolutely normal behavior, but if it weren’t a DNS server, that kind of behavior could be a sign of an attack.
In addition to context, we need to build systems with expert knowledge. Ideally systems that help us capture expert knowledge in simple ways. This is very different from throwing an algorithm at the wall and seeing if it yields anything potentially useful. One of the interesting approaches in the area of knowledge capture that I would love to see getting more attention is Bayesian belief networks. Is anyone done anything interesting with those in security?
We should also consider building systems that do not necessarily solve all of our problems right away, but can help make security analysts more effective by assisting them in their daily routines and in their work. Data visualizationis a great candidate in that area. Instead of having analysts look at thousands of rows of data, they can look at visual representations of the data that unlocks a deeper understanding of the data in a very short amount of time. It’s also a great tool to verify and understand the results of machine learning applications.
In Zen, koans are just a tool or a building block to get to the end goal. Just like machine learning, it’s a tool that you have to know how to apply and use in order to come to new understanding and find attackers in your systems.
Guest post © by Raffael Marty — Follow him on twitter and check out his blog.
No comments:
Post a Comment